Information Theory and Coding > Data Compression > What is Huffman Coding?
Huffman Coding:
A variable length encoding algorithm Huffman code was created by American, D. A. Huffman, in 1952. Huffman`s procedure is applicable for both Binary and Non- Binary encoding. It is based on the source symbol probabilities P(xi) i = 1, 2, ... , n. The algorithm is optimal in the sense that the average number of bits it requires to represent the source symbols is a minimum, and also meets the prefix condition. The steps of the Huffman coding algorithm are given below:
For binary encodings, when q = 2 (i.e. X = {0,1}). The algorithm constructs a binary tree, as follows.
- First, order the letters i ∈ I so that p1 ≥ p2 ≥···≥ pm.
- Assign symbol 0 to letter m−1 and 1 to letter m.
- Construct a reduced alphabet Im−1 = {1,...,m − 2,(m − 1,m)}, with probabilities
p1,..., pm−2, pm−1 + pm.
- Repeat steps (i) and (ii) with the reduced alphabet, etc.
We obtain a binary tree
The above algorithm can be explain in words without the use of mathematical symbols
- Arrange the source symbols in decreasing order of their probabilities.
- Take the bottom two symbols and tie them together as shown below. Add the. probabilities of the two symbols and write it on the combined node. Label the two branches with a '1' and a '0'.
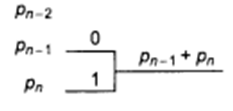
- Treat this sum of probabilities as a new probability associated with a new symbol. Again pick the two smallest probabilities, tie them together to form a new probability. Each time we perform the combination of two symbols we reduce the total number of symbols by one. Whenever we tie together two probabilities (nodes) we label the two branches with a '1' and a '0'.
- Continue the procedure until only one probability is left This completes the construction of the Huffman tree.
- To find out the prefix codeword for any symbol, follow the branches from the final node back to the symbol. While tracing back the route read out the labels on the branches. This is the codeword for the symbol.
A pictorial example are given bellow:
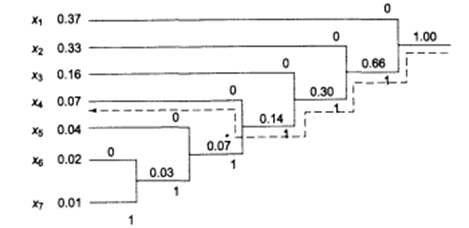
Consider a random variable X taking values in the set X = {1, 2, 3, 4, 5} with probabilities 0.25, 0.25, 0.2, 0.15, 0.15, respectively. Construct a Huffman optimal binary code and ternary code for X. Also Calculate average length of coding.
For binary code:
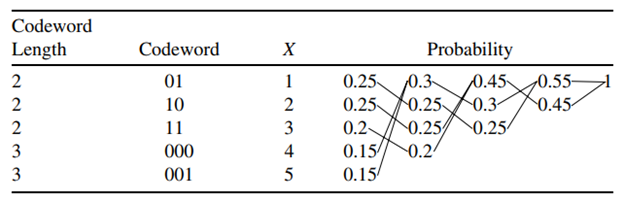
This code has average length =2*0.25+ 2*0.25+2*0.20+ 3*0.15 + 3*0.15 = 2.3 bits.
For binary code:

This code has an average length of 1*0.25+ 1*0.25+2*0.20+ 2*0.15 + 2*0.15 =1.5 ternary digits.
Home Work:
Suppose that letters i1,...,i5 are emitted with probabilities 0.45, 0.25, 0.2, 0.05, 0.05. Compute the expected word-length for Shannon– Fano and Huffman coding. Illustrate both methods by finding decipherable binary coding in each case
Feedback
ABOUT
Statlearner
Statlearner STUDY
Statlearner