Big Data > Spark > a. Standalone Cluster Manager
Standalone Cluster Manager
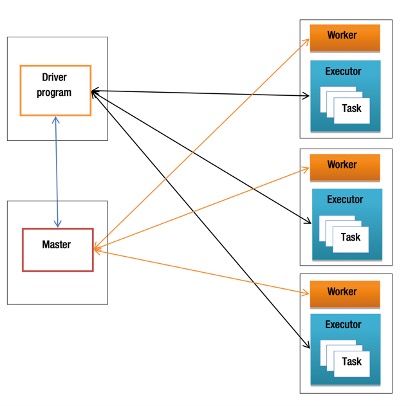
The Standalone cluster manager comes prepackaged with Spark. It offers the easiest way to set up a Spark cluster. The Standalone cluster manager consists of two key components: master and worker. The worker process manages the compute resources on a cluster node. The master process pools together the compute resources from all the workers and allocates them to applications. The master process can be run on a separate server or it can run on one of the worker nodes along with a worker process.
When a Spark application is deployed using the Standalone cluster manager, it consists of three main components: the driver program, executors, and tasks. The driver program is the core application that utilizes the Spark library and contains the logic for processing data. It is responsible for coordinating the execution of jobs across the cluster.
Executors are Java Virtual Machine (JVM) processes that run on worker nodes. These executors carry out the actual data processing tasks assigned by the driver. Each executor can run multiple tasks in parallel and also manages memory used for caching intermediate data.
To begin execution, the driver program establishes a connection with the cluster through a SparkContext object. This object serves as the main gateway to the Spark framework. It communicates with the master node to request computing resources from the cluster. Once resources are allocated, SparkContext initiates executors on the available worker nodes and sends them the application code. The driver then divides the overall job into smaller tasks and distributes them to the executors for parallel execution.
Feedback
ABOUT
Statlearner
Statlearner STUDY
Statlearner